
This is a story concerning creation, born of necessity, of a decent search engine which runs on local production Linux machines. It has requirements of being totally under our control (nothing is in the cloud nor in a vendor’s store), do respectable full text searches on many document types, provide individual sets of one or more search indices securely for different users, work well with a variety of user devices, support UTF-8, be parsimonious about system resources, scale well to huge (million+) document collections, and be free. My approach was first to become familiar with existing components, next define the important objectives, and then implement a solution.
The story begins with an original environment: using Novell’s QuickFinder search engine on local Linux servers. Alas, QuickFinder was recently retired, and that led to the current project. The obvious (to me) choice was the Apache Solr/Lucene search engine project1 which is open source and runs on Linux. Lucene is the engine and Solr is its wrapper providing web services and more. They are complex and initially daunting.
After spending suitable time learning about Solr I went to an Apache Solr companion project named Nutch which provides web and local file crawling and feeds results into Solr/Lucene. Unfortunately, Nutch material was huge (240+MB plus GBs of working space), very awkward and easily pushed Solr into overload mode (GBs of memory and disk). Nutch was not acceptable for what I intend. I also needed a user query program and Solr internal controls.
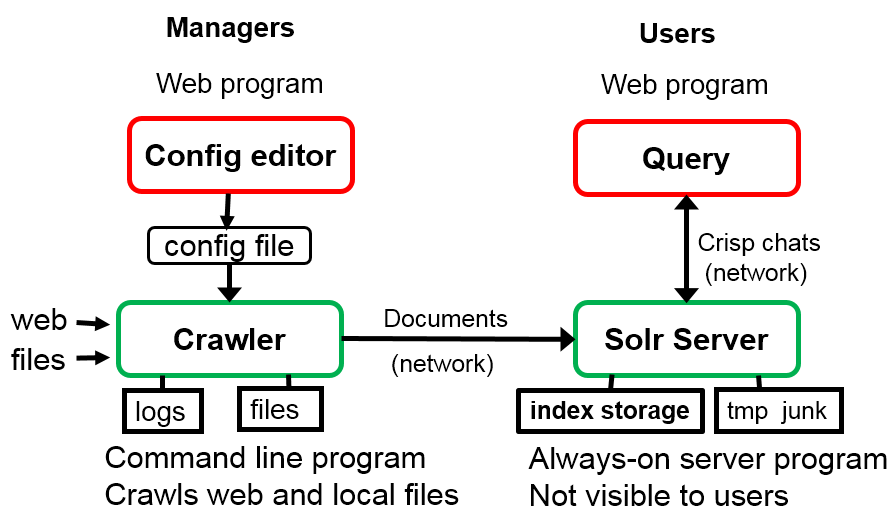
Crawler and Query programs
I created a new crawler program to acquire files from either the local file system where the crawler resides or from remote web servers. The crawler is instructed about which files to index and which to ignore by using effective yet simple rules which a user can readily construct. I then needed to figure out how to feed files into Solr in a manner which it could absorb gracefully; that did take some thinking and testing.
The resulting crawler, 37KB of PHP, is much smarter and smaller than Nutch, and able to deal with some rather complicated web pages. The crawler reads a small configuration file for each index, which in turn meant creating a simple web based configuration editor to construct such files. Overall the project material works fine with PHP v5.3 through the current v7.x and a range of Solr editions up to the present moment, and it is designed to accommodate frequently changing Solr versions.
Next on the to-do list was accepting web queries from users and providing nice results. That became a web based query program, 29KB of PHP, which is friendly to users whether via their desktops or mobile devices, is considerate of screen space and bandwidth, and is helpful. The design has some interesting construction rules, including how to move about within a large collection of results.
Let us start with the web based crawler configuration program and discuss selecting files.
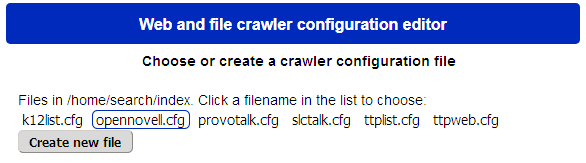
Configuration files are stored beneath the program in a subdirectory named index. I have placed the whole thing in /home/search on my systems. Choose to create or edit a configuration file, and that results in a seemingly complicated screen, but we separate it into three simpler areas. The top portion as shown in figure 3 concerns the index name and which files to include:
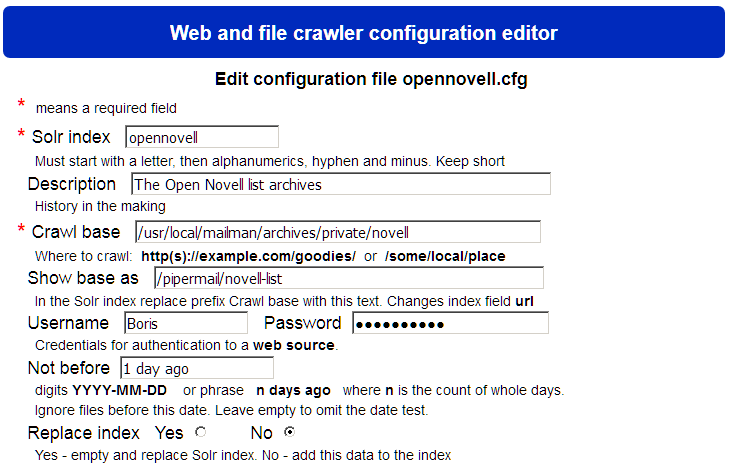
The “Solr index” field has the text which also will show on the user’s query program as the title of a button, thus it needs be short. Then we get to the interesting part.
The “Crawl base” field specifies where to find files. A decision is made by recognising that if the field starts with four characters http then do a web based search, otherwise explore the local file system. Parallel to it is a “Show base as” field which allows the crawl base text to be shown to users as another string (such as crawl local files directly for efficiency, but offer them to users via appropriate web URLs).
Two other fields are interesting: “Not before” specifies ignoring files older that a certain date (with convenient syntax), and “Replace index” to empty the index or just add to what is already present. Together these two fields support incremental updates, say overnight, and thus avoid a full index rebuild. A quiet nuance is if new files replace older ones in an index then the crawler deletes the old ones from the index after a certain number (100, defined in the program) accumulate.
The middle portion of the screen, figure 4, concerns selecting files, and some discussion is beneficial.

The selection strategy is to acquire a filename and then examine the rules from the top down to see if it matches a pattern. The first match ends the examination, but if no rule matches then accept the file. Comments are semicolon to end of line. Active rules start with a plus (accept) or minus (ignore) sign followed by the pattern to be matched. The pattern is a simple regular expression.
The example in figure 4 can be translated into ordinary English.
- Several comment lines (;) start the rule box.
- The first active rule says ignore (-) filenames of database or attachments or pipermail.pck. Note use of () to group the OR choices.
- The second active rule says ignore if matching author or date or subject or thread, where each terminates in .html.
- The third active rule says ignore files having extension of .txt (.+ for some characters, a literal dot \., txt).
- Next is a general purpose accept (+) rule which says files having a base (.+) followed by a literal dot (\.) and then a variety of common extensions (word processor material, PDFs and so on).
- The last rule says ignore other files having an extension.
The fall through of no matches is to accept. This method is simple and compact. Several further menu details, about Solr control, are discussed in the installation document.
With a selected config file the main menu changes to show its summary plus five operating controls, as shown in figure 5.
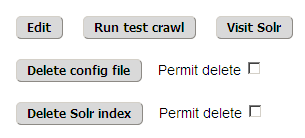
The crawler is normally run via a scheduler (say cron), which can be done with scripts such as:
#! /bin/bash
# Crawl using config file myindex.cfg, option -v to view live logging
cd /home/search
php crawler.php index/myindex.cfg
To finish up the crawler area, here are some of the rules for looking about:
- Both file and web crawls: stay within the starting place
- Solr indexing is slow, be clever, feed Solr one file at a time
- File crawl: skip symbolic links and hidden (dot) files
- Web crawl: index static web pages but not dynamic ones
- Deal with complex web layouts
- Avoid indexing the same file multiple times
- Accept web page href’s with ../ but stay within bounds
- Accept web page href’s with blah#foo but remove #foo
Queries and Search Results
Program query.php supplies results. Often many copies of it are used, each showing a particular set of indices for an audience. Audience selection is done externally, say an Apache web server. The query program is intended to be easy to use, quick (0.1 sec response time), with least clutter. It uses buttons (aside from the search text box) so that clicking any button causes a fresh search while retaining other settings.
It is friendly to touching fingers and a wide variety of web browsers. The slider below is three lines of internal-only javascript. Search state is carried within each web request and response, not kept on the server, thus a large number of simultaneous clients can be supported.
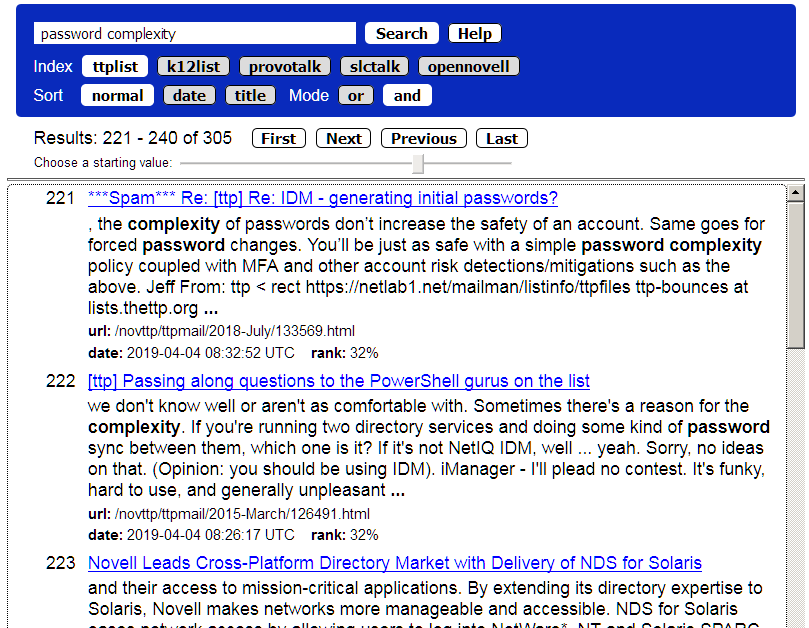
Some points to note. The control block remains fixed at the top of the screen and results are scrollable beneath it, thus easy control. Matched terms in a text body search are highlighted in the displayed content snippet. Titles are clickable, naturally, but what is a title of a file varies with the file so the program tries to find a reasonable string to display.
That string may be a formal title if the Solr parser discovers one in the text, or the filename as a fallback. If there were only one index available then the Index row is not shown. Clicking a button results in about ten network packets, and the response is quicker than we can click things no matter the index size.
Search syntax is Google-like, more or less, and normally case insensitive. OR and AND buttons choose finding files with any (OR) of the search terms, or all (AND) of them. A “quoted string” counts as one literal term. A minus sign prefix means the item must not occur, a plus sign prefix insists that an item occurs. These supplement the OR/AND button setting.
An example is wanting all references to OES but no .PDF mentions: do a search on phrase OES -.pdf. For the special url: field the underlying parser is simple case sensitive Lucene, thus use phrase url: .pdf to find only .pdf files. The Help menu has examples. Date: is either from the file if its date is discoverable, otherwise it is the time of indexing.
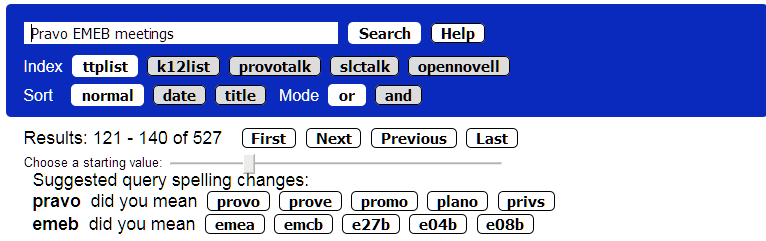
The service provides a basic “did you mean” typo catcher which offers correction terms. Click on a suggestion to apply it to the search string. Figure 7 has an example. This is a simple yet useful approach, but it is not Artificial Intelligence making clever inferences. Please don’t take this personally Alexa and Siri; Google please sit down and be quiet.
There are several manager controls within query.php. An important one is the list and order of indices which this copy of the program is permitted to use. That is line:
$indexlist = array(“ttplist”, “k12list”, “opennovell”);
Different lists for different audiences, and users cannot subvert this list by cute web tricks.
The query program can be invoked within web pages by using a normal <a href=…> clause. Both index (index=) and search text (q=) may be passed as part of the URL, such as about Waterloo
<a href=”query15.php?index=history&q=Waterloo” “target=”_blank”>search</a>
Performance and Resource Requirements
This brings us to resource consumption. The crawler configuration web program is 26KB of PHP including comments, the crawler is 37KB of PHP and uses about 8-15MB of running memory, and the query program is 29KB of PHP. Solr/Lucene (Java material) uses 190+MB disk, plus indices, and about 1.4GB memory. CPU utilisation during indexing remains moderate and non-interfering with regular activities, by design. A separate search machine is not a necessity.
Performance. Indices are usable while building. Testing shows simple text files go at up to 10 per second. Complex files go at about 1-3 per second. Indexing 2840 word processor files took 30 minutes, 80 PDF files took 1.5 minutes. Incremental updates go very quickly indeed, say 35 new email messages in 0.4 minutes (24sec to cull a file store of 135,000 messages then index 35 more). A file store of 664,138 email messages (24GB worth) resulted in 9.8GB of index material.
Future Direction?
Solr/Lucene provides two “local cloud” architectures: replicating indices between like Solr’s, and splitting storage of an index across many machines which then hold “index shards.” The Solr project has many supplements of various kinds which can be investigated. The present search facility has not exploited these added features. The search service installation manual also discusses how to keep the schema bundle compatible with constantly changing Solr/Lucene releases.
Referrals
- For Apache Solr visit https://lucene.apache.org/solr
- Download the Search Service along with further presentations and material from https://netlab1.net/
- Go to the “Solr/Lucene Search Service” area. which includes the items below
- SearchService2.pdf – an overview
- Installing Search Service v2.1.pdf
- SearchService2.1.tar.gz – programs, schema bundle plus PDFs above
This article was first published in OH Magazine, Issue 44, 2019.2, p15-18.