by Walter Lucero, Matt Kereczman and Greg Eckert
Introduction
As we mentioned in our previous article (in OHM26), High Availability is the act of ensuring business continuity with 99.999% up-time, despite a component failure.
One popular solution is LINBIT’s open source product, DRBD. It is used for High Availability Linux clustering. By connecting two of your existing Linux servers together, and installing DRBD, your company can replicate its data, in real time, to protect digital information and ensure that services stay up and running. No matter what type of data – Customer records, intellectual property, virtual machines, financial – If your back-end systems run on Linux, and you can write your data to a SAN, NAS, iSCSI or local hard drives, DRBD can replicate the data to ensure that you never lose business because of unexpected downtime and data loss even in the event of hardware failure.
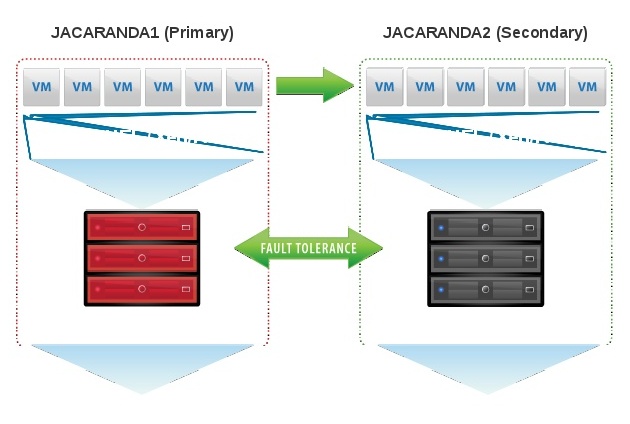
In Figure 1 the two boxes represent two servers that form a HA cluster. The boxes contain the usual components of a Linux™ kernel, file system, buffer cache, disk scheduler, disk drivers, TCP/IP stack and network interface card (NIC) driver. The blue arrows illustrate the flow of data between these components. The green arrows show the flow of data, as DRBD mirrors the data of a highly available service from the active node of the HA cluster to the standby node of the HA cluster.
DRBD, is available for download at www.linbit.com. Up-time guarantees, as well as service and support options, bug fixes, and certified binaries are available through LINBIT’s Enterprise Support Subscriptions. Of course If you are building a cluster we would recommend SUSE Linux Enterprise Server or Red Hat Enterprise Linux because of their corporate services and support.
In this article, we will show how to implement a High Availability solution for one common and typical scenario; building HA into your current Xen/KVM environment.
Xen-HA
Xen and KVM are both in-kernel Hypervisors for the Linux platform. Xen/KVM create virtual machines (domains) which run in completely isolated environments on the same physical hardware as their host. Xen/KVM has been available for Linux since early versions of the 2.6 kernel; Xen and Kvm are the default hypervisors in many modern Linux distributions. Virtualization relies on support in hardware; the relevant CPU extensions are known as VT for Intel, and SVM for AMD.
The solution described in this article applies to DRBD which is a “shared nothing replication solution”. This makes it possible to achieve the highest degree of availability in your virtualized infrastructure without an expensive shared storage solution such as a SAN or NAS. With the DRBD device being local to the node, this will also reduce the overhead in read I/O associated with network attached storage. Presently, this solution does not allow for live migration of the Virtual Domains without using a Dual-Primary DRBD configuration, and a clustered file system. This feature is currently not available for Active-Passive clusters.
In order to create a highly available Xen/KVM environment, you will need to install the following software packages.
- Corosync is the cluster messaging layer supported by Pacemaker, which you may use in place of Heartbeat. Corosync is the only supported Pacemaker messaging layer in current versions of Red Hat Enterprise Linux and SUSE Linux Enterprise Server. Other distributions ship both Corosync and Heartbeat. For the sake of simplicity, this technical guide presents the solution on just one messaging layer, which is Corosync.
- Xen/KVM is the virtualization facility that manages domains. It requires an Xen/KVM-enabled Linux kernel, a CPU with VT or SVM support enabled in the BIOS, and the Qemu hardware emulator (usually named qemu, qemu-kvm, or similar). This guide assumes you are familiar installing and configuring Xen/KVM, so we can say you are currently running a few Xen/KVM VMM hosts with all the hypervisor packages installed and configured.
- Pacemaker is a cluster resource management (CRM) framework which you will use to automatically start, stop, monitor, and migrate resources. Distributions typically bundle Pacemaker in a package simply named Pacemaker. This technical guide assumes that you are using at least Pacemaker 1.1.11.
- Libvirt is an abstraction and management layer for KVM and other hypervisors. The configuration explained in this guides requires the libvirt library, and the associated set of binary tools. The corresponding packages are usually named libvirt and libvirt-bin, respectively.
- DRBD is a kernel block-level synchronous replication facility which serves as an attached, shared-nothing, cluster storage device. This article assumes the use of DRBD 8.4.4. LINBIT support customers can get pre-compiled binaries from the official repositories. [http://packages.linbit.com] As always, the source can be found at http://www.drbd.org.
Please note that you may be required to install packages other than the above-mentioned due to package dependencies. However, when using a package management utility such as Yast, yum, or zypper, these dependencies should be taken care of for you, automatically.
After you have installed the required packages, you should take care of a few settings applying to your boot process, using your distribution’s preferred utility for doing so (typically either chkconfig or insserv).
There are two options for installing all the above packages:
1. Install SUSE HAE or RHEL HAE as an Add-On. You need a SLES activation code to test with. With that set, you can install DRBD and Pacemaker (which would include Corosync/OpenAIS).
2. LINBIT repositories. Certified binaries provide customers one more benefit for purchasing support.
Adding repositories:
# zypper addrepo
http://packages.linbit.com/<HASH>/yum/
sles11-sp3/drbd-8.4/x86_64 DRBD-8.4
# zypper refresh
<accept the key>
Install DRBD:
# zypper install drbd drbd-kmp-default
Install heartbeat and pacemaker:
# zypper install heartbeat pacemaker
Make sure that:
- Libvirtd init script does start on boot. This will allow distribution of virtual domains across both nodes, and allow for off-line migration of the domains.
- Configure NTP on both nodes.
- Apply all the OS patches published by SUSE or Redhat.
- The network layout is appropriately configured and understood (firewalls, IP addresses, etc).
- You have configured either DNS or both node’s /etc/hosts files.
You then have the cluster stack installed - its time to configure the HA solution.
Preparing the backing block devices to replicate with DRBD
Imagine that block devices sdb and sdc are LUN’s or local devices you want replicate.
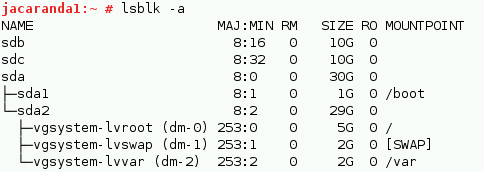
You need to create physical volumes and volume groups

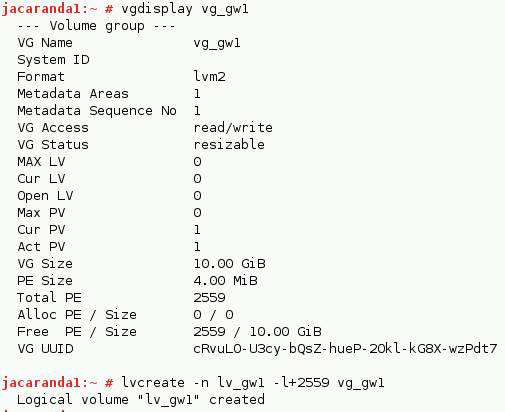
Check your volume group and then create a logical volume, as shown below.
Once we have installed the HA packages, and prepared the DRBD backing devices (LVMs), it is necessary to configure the DRBD resources to serve as the virtual disks for the Xen/KVM virtual instances.
It is recommended that you use a separate DRBD resource for each individual virtual machine. The suggested method is to use individual logical volumes as the backup device for each DRBD resource.
While this is not absolutely necessary, it will provide a degree of granularity and allow you to distribute the VMs across different nodes; rather than having all VMs always run on a single node. One must also be careful not to over-commit system resources; ensure your systems are able to run all VMs in the event of a single node failing.
It is highly recommended that you put your resource configurations in separate resource files that reside in the /etc/drbd.d directory, whose name is identical to that of the resource. For example, I will use the name of common Argentine trees like Ceibo (dbrd resources) and Jacaranda (Xen hosts).
DRBD
Create resource file for the os: /etc/drbd.d/ceibo-os.res
#vDisk0 where the OS is installed
resource ceibo-os {
device /dev/drbd0;
disk /dev/vg_gw1/lv_gw1
meta-disk internal;
on jacaranda1 {
address 10.0.1.253:7790;
}
on jacaranda2 {
address 10.0.1.254:7790;
}
}
Then create the resource file for the data volume: /etc/drbd.d/ceibo-data.res
#vDisk1 where there are GroupWise databases for example – or it can be a File-Server or another DB like MySQL/PostgreSQL
resource ceibo-data {
device /dev/drbd1;
disk /dev/vg_gw2/lv_gw2
meta-disk internal;
on jacaranda1 {
address 10.0.1.253:7791;
}
on jacaranda2 {
address 10.0.1.254:7791;
}
}
Next copy the config to peer
# scp /etc/drbd.d/* root@jacaranda2:/etc/drbd.d/
# scp /etc/drbd.conf root@jacaranda2:/etc/
Create metadata and start the resources on both nodes:
# drbdadm create-md ceibo-os
# drbdadm create-md ceibo-data
# insserv drbd
# reboot
The next step is to promote resources to Primary on one node:
# drbdadm primary ceibo-os --force
# drbdadm primary ceibo-data –force
We have to use the force parameter because drbdadm won’t let us promote to Primary without ‘UpToDate’ data.
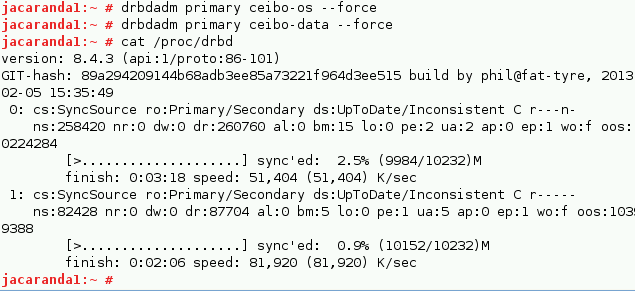
You can then watch the initial sync:
# watch -n1 cat /proc/drbd
You can use your resource during the sync on the Primary.

Assign the DRBD devices to a new Virtual Machine.
In practice
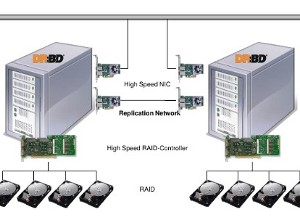
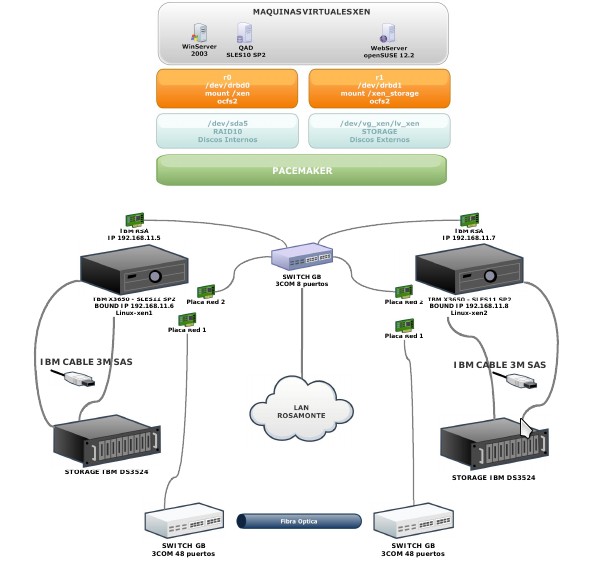
The schematic in figure 2 shows how DRBD is installed at one customer; using DRBD to replicate between two IBM Storage DS3524 units. Rosamonte produces yerba mate tea in Argentina.
Conclusion
With DRBD, High Availability is no longer an expensive project and this article shows how it can be implemented. We have customers with different needs:
- Using SUSE, RHEL, Debian, Ubuntu Server LTS as Xen/KVM servers running numerous VMs using DRBD for HA with relocation features.
- Running critical services without virtualization that need HA (ex. Web servers, Databases, Mail, File server, etc).
- Replicating IBM/Dell/HP expensive storage units without the need to buy expensive vendor replication licensing.
[Mat Kereczman and Greg Eckert work for LINBIT in the USA]
(This article first appeared in OHM28, 1-2015, p11-14).